Über dbs|GKV AU
Voraussetzungen
Zur Erkennung der Metadaten einer AU-Bescheinigung werden zunächst innerhalb der d.capture batch Position pdf417 analyser gegebenenfalls erkannte 2D Barcodes vom Typ PDF417 ausgewertet und mit Stammdaten angereichert.
Basis für die Auswertung ist das Technische Handbuch Blankoformularbedruckung der Kassenärztlichen Bundesvereinigung in der jeweils aktuell gültigen Version.
Sollte kein Barcode erkannt worden oder dessen Auswertung gescheitert sein, wird die AU-Bescheinigung anhand des Volltextes (OCR) mit Hilfe von d.classify analysiert.
Dies findet in d.capture batch innerhalb der Position classify analyser statt. Das d.classify Modul von dbs | GKV AU unterscheidet zunächst zwischen zwei unterschiedlichen AU-Formulartypen, den rosafarbenen Leerformularen (plain_form) und den gelben Formularen mit rot aufgedruckten Formularfeldern (printed_form).
Beim Formulartyp printed_form ist für die Erkennung die Verwendung eines roten Farbfilters beim Scann erforderlich, so dass nur noch der aufgedruckte Text übrig bleibt. Beim Formulartyp plain_form werden vom Arzt sowohl das Formular, als auch die Metadaten in schwarzer Farbe gedruckt. Somit wirkt sich ein Farbfilter hier nicht aus.
Die Erkennung der Attribute geschieht innerhalb von Zonen und meist unter Zuhilfenahme regulärer Ausdrücke. Zonen lassen sich relativ und ausgehend von einem markanten Merkmal bestimmen. Hierzu wird jedes dbs | GKV AU Modul vom Setup kundenspezifisch erstellt, denn wesentliche Ankerpunkte sind der Name und die Nummer der Krankenkasse.
In unserem Demosystem hat die imaginäre d.velop BKK die Kassennummer 4604711 und die d.velop BKK/Ost die Nummer 4604712.
In der folgenden Abbildung wird beispielhaft die Erkennung des Geburtsdatums anhand beider Ankerpunkte angezeigt.
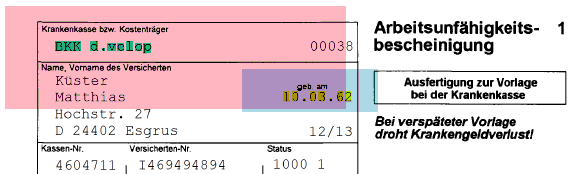
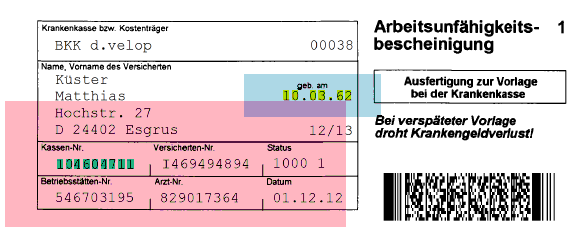
Der bereits angesprochene reguläre Ausdruck sorgt weiterhin dafür, dass nur plausible Daten tatsächlich berücksichtigt werden.
Im Falle des Geburtsdatums lautet der Ausdruck \b[0-3][ ]?[0-9][. ]{0,3}[0-1][ ]?[0-9][. ]{0,3}((19)|(20))?([0-9][ ]?){2}\b. Wie man an dem Beispiel mit entsprechenden Kenntnissen erkennen kann, wurden typische Erkennungsfehler und unterschiedliche Schreibweisen bereits berücksichtigt. So wird das Datum sowohl mit zwei-, als auch mit vierstelliger Jahreszahl erkannt und auch nicht erkannte Punkte werden vom System eigenständig hinzugefügt.
Liefert die Zeichenerkennung (OCR) jedoch nicht plausible Daten, wie ein B statt einer 8, wird der Wert aufgrund des regulären Ausdrucks verworfen. Im Falle des Geburtsdatums wäre eine Nicht-Erkennung noch nicht tragisch, da die Person ebenso gut anhand der Versicherten-Nr. erkannt werden kann. Fehlende oder nicht korrekt erkannte Angaben werden im Anschluss anhand der vorhandenen Stammdaten des iskv_21c Replikats ergänzt.
Die jeweils verwendete Erkennungsmethode wird Ihnen im Index angezeigt.
